NLP Sentiment Analysis - A POC for User Research
Problem
Solution
1
2
3
4
5
6
7
8
9
10
from transformers import pipeline
import pandas as pd
import numpy as np
import re
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from wordcloud import WordCloud
from wordcloud import STOPWORDS
from collections import Counter
from sklearn.metrics import accuracy_scoreUsing Pre-trained Models with Huggingface 🤗
1
model = pipeline(model = "nlptown/bert-base-multilingual-uncased-sentiment")Balancing Data
1
2
3
4
reviews = pd.read_csv('20191226-reviews.csv')
# rename body to reviews
reviews.rename({'body':'review'}, axis = 1, inplace = True)items = pd.read_csv('20191226-items.csv')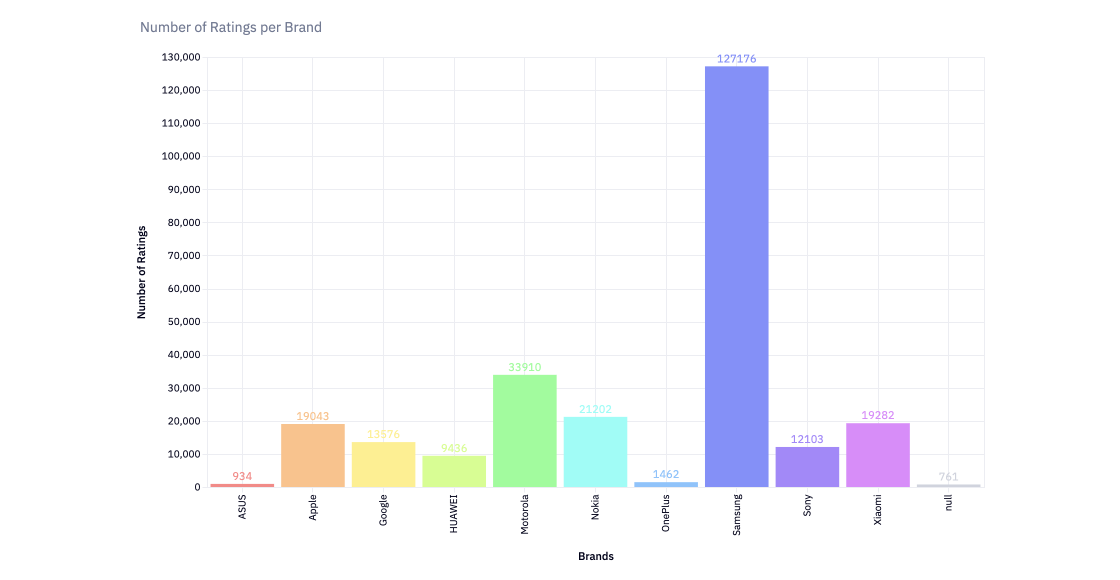
Preprocess Data
To minimize processing time, all data was dropped where there wasn't a valid review or company name present.
1
dataset = dataframe.dropna(subset = ['brand', 'review'])Prdicting User Sentiment
1
2
reviews = subset['review'].tolist()
ratings = model(reviews, truncation = True)1
[{ 'label': '2 stars', 'score': 0.1618033988749894 }]1
2
3
4
predicted_rating = [int(r['label'][0]) for r in ratings]
rating_confidence = [round(r['score'] * 100, 2) for r in ratings]
subset['predicted_rating'] = predicted_rating
subset['rating_confidence'] = rating_confidence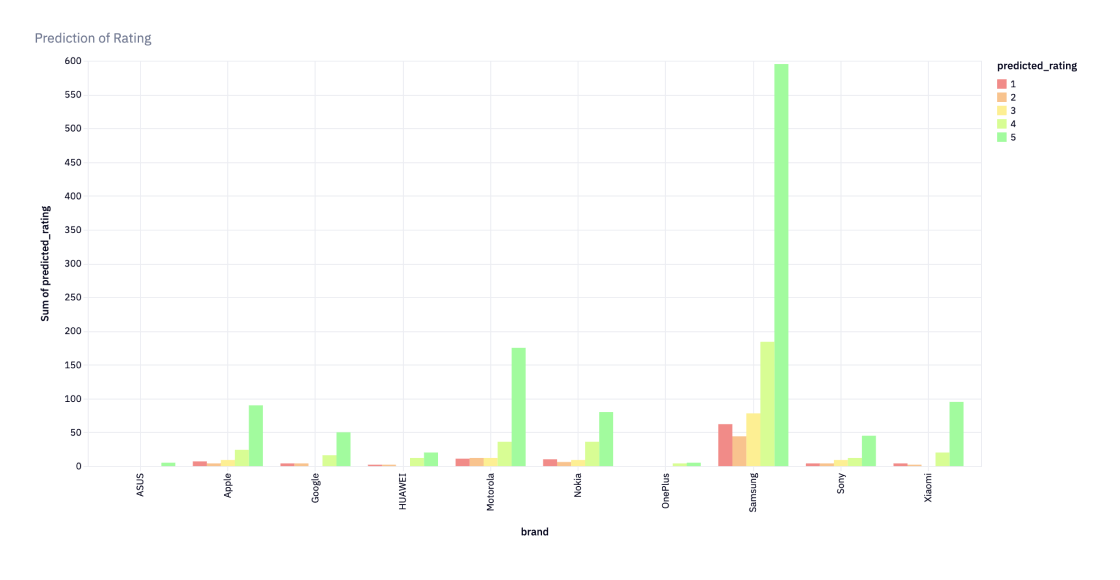
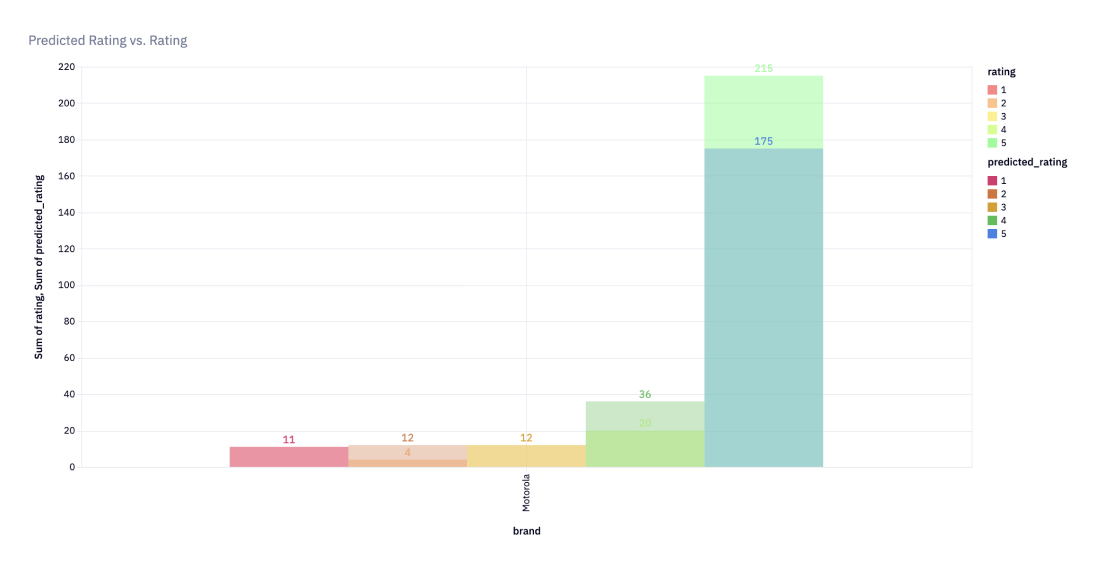
To get a more indepth understanding, the data was filtered by brand and charts were used to get a better view of the prediction of rating in comparison to the actual rating. This was helpful with evaluating the findings.
Results
Performance of how well the model did at predicting sentiment as well as the predictions themselves were used to learn something about customer satisfaction for each company.
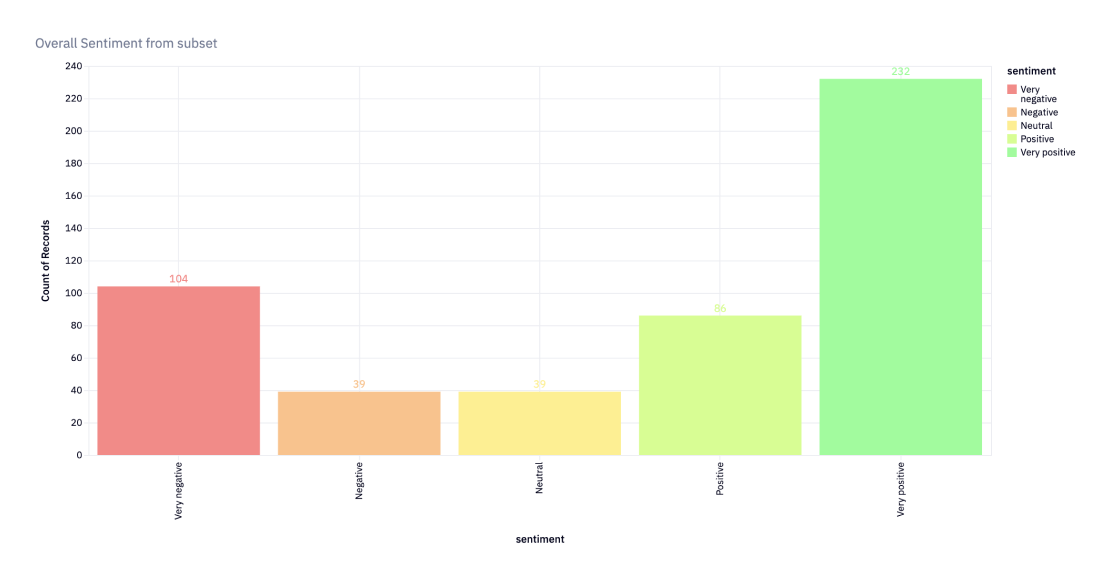
Since the original dataset contains the actual rating for each review, an accuracy score could be calculated to get an idea of how well the model performed. A way to convert star ratings to sentiment was also created.
1
2
3
4
5
6
7
8
labeler = {
1: 'Very negative',
2: 'Negative',
3: 'Neutral',
4: 'Positive',
5: 'Very positive'
}
subset['sentiment'] = subset['predicted_rating'].apply(lambda rating: labeler[rating])Very negative
Rating of 1Negative
Rating of 2Neutral
Rating of 3Positive
Rating of 4Very positive
Rating of 5Now a clear view of the overall sentiment could be seen.
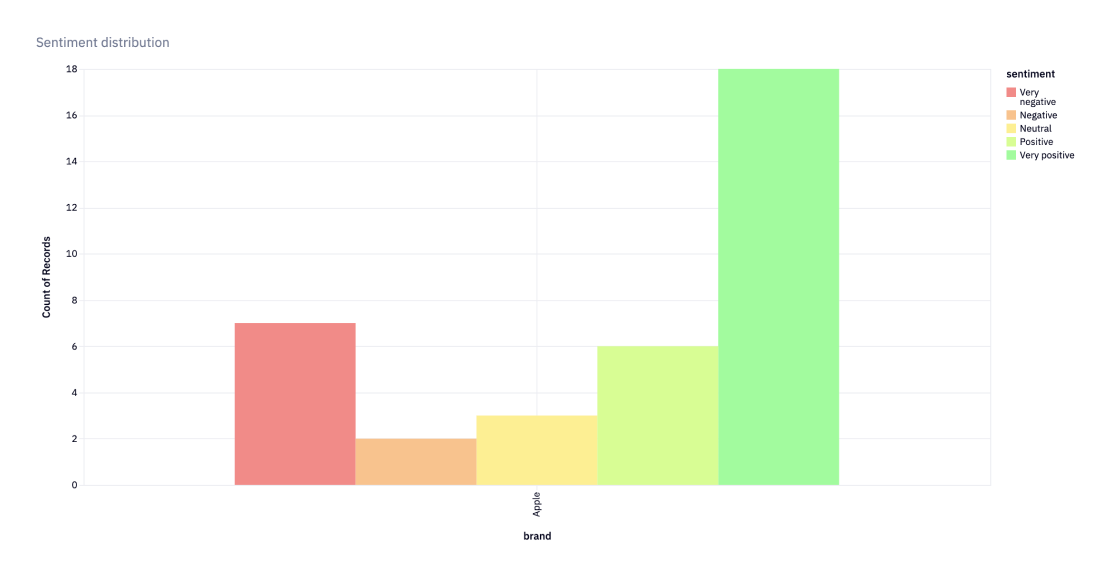
The results of the model could also be used to create a report that showcases the percentage of each sentiment category for all reviews for each company. By example here we are looking at a report of Mototorola negative review comparing the actual rating vs predictied rating along with the confidence of the prediction.
1
Actual Rating2
Predicted Rating57.72
ConfidenceAlthough this is a good way to measure performance per company, it isn't a very good method for understanding how one company may compare to others since there aren't an equal number of observations for each.
Word Cloud
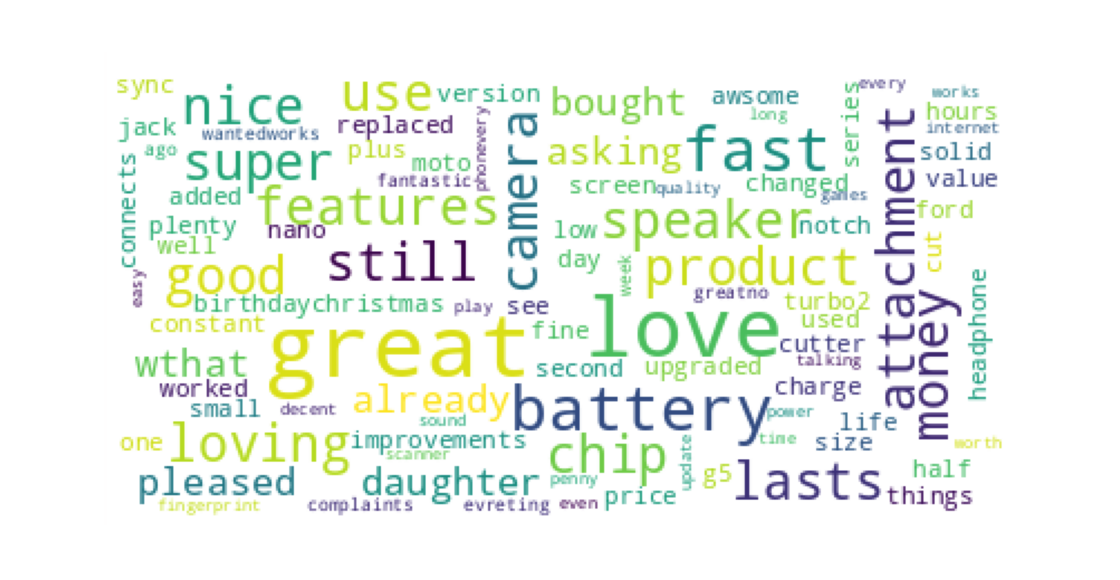
Lastly, a word cloud visualization was created to give an idea of the words commonly associated with each sentiment of category. By example below is a word cloud generated by the filtering of "Very positive" reviews of Motorola from the data.